

In de vorige Deep Learning blogpost hebben we gezien hoe neurale netwerken kunnen worden gebruikt als computationeel efficiënte functiebenaderingen. In theorie kunnen we dit voor quasi ieder probleem gebruiken, al is er één fundamentele beperking: computers werken met getallen.
De uitdaging is daarom niet alleen om een neuraal netwerk te trainen, maar ook om een probleem om te zetten naar een verzameling getallen die als invoer voor dat netwerk kunnen dienen. In deze post bekijken we hoe zulke transformaties werken aan de hand van regressie- en classificatieproblemen.
Stel dat we een dataset hebben met tweedehandswagens. Voor elke wagen kennen we volgende parameters.

Ons doel is een AI-model te trainen dat op basis van deze eigenschappen de verwachte verkoopprijs kan voorspellen.
Conceptueel veronderstellen we dat er een functie bestaat:
Prijs = f(Merk, Jaar, Afstand, Brandstoftype, Conditie)
De dataset bevat voorbeelden van deze functie, maar we willen eveneens prijzen kunnen voorspellen voor nieuwe combinaties van relevante eigenschappen. Hoe gebruiken we nu een neuraal netwerk om deze functie te benaderen?
Van eigenschappen naar getallen
Een neuraal netwerk verwacht numerieke invoer. We weten dat een neuraal netwerk een variabele hoeveelheid input en output neuronen heeft. Ieder input neuron ontvangt daarbij één getal. Voor dit probleem kunnen we simpel stellen dat we 5 input neuronen nodig hebben en 1 output neuron.
Voor sommige eigenschappen is dit eenvoudig:
- Jaar is een getal.
- Afstand is eveneens al een getal.
Voor andere eigenschappen moeten we eerst een representatie bedenken.
Binaire categorieën
Voor het Brandstoftype kunnen we stellen dat de wagen elektrisch of op diesel rijdt:
- Elektrisch → 0
- Diesel → 1
Omdat er slechts twee mogelijke waarden zijn, kunnen we deze eigenschap rechtstreeks voorstellen als een booleaanse variabele.
Geordende categorieën
Merk en Conditie zijn eigenschappen met meer dan 2 categorieën. Bij Conditie bestaat een natuurlijke hiërarchische volgorde. We kunnen deze relatie behouden door iedere unieke Conditie te vervangen door een numerieke waarde:
- Nieuw → 2
- Goed → 1
- Gebruikt → 0
One-hot encoding
Bij het Merk is deze hiërarchie helemaal niet duidelijk, of zelfs veranderlijk. We kunnen eenzelfde mappingtabel zoals hierboven opstellen, maar een betere oplossing voor dit soort data is one-hot encoding. In plaats van één invoerveld gebruiken we dus drie afzonderlijke neuronen:
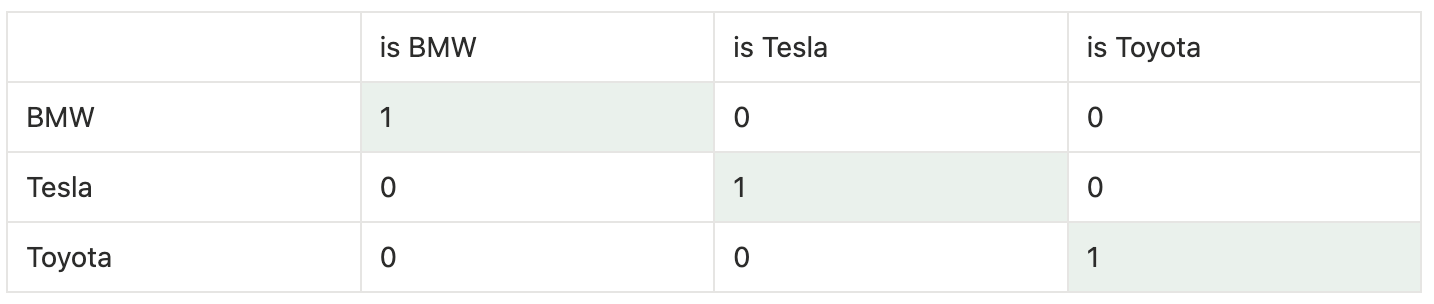
We geven op deze manier geen expliciete volgorde mee aan de data, al hebben we dan wel meer input neuronen nodig voor slechts 1 parameter.

Het netwerk
Voor de 5 gebruikte parameters hebben we dus 7 input neuronen nodig. Deze datasetrij wordt uiteindelijk een lange lijst getallen die rechtstreeks aan het netwerk, het Deep Learning Algoritme, kan worden aangeboden.
Na training kunnen we voor nieuwe wagens dezelfde transformatie uitvoeren, van:

naar:
Vervolgens geven we deze resulterende getallen aan het netwerk. In plaats van de uitvoer te gebruiken voor foutberekening en backpropagation, interpreteren we de output nu als de voorspelde prijs van de wagen.

Van afbeeldingen naar classificatie
Het vorige voorbeeld sloot vrij goed aan bij de structuur van een neuraal netwerk. Veel invoergegevens waren immers al numeriek. Een domein waar de transformatie complexer is, onder andere door de human feel, is image processing.
Toch vormen beeldverwerking en classificatie één van de bekendste toepassingen van Deep Learning. Denk bijvoorbeeld aan:
- Handgeschreven cijfers herkennen
- Het verschil detecteren tussen een chihuahua en een muffin
- Objecten herkennen op foto's
De uitdaging blijft dezelfde: hoe zetten we een afbeelding om naar een verzameling getallen, een bruikbare input voor een neuraal netwerk?
Flattening
Een afbeelding bestaat uit een raster van pixels. Bij een zwart-witafbeelding bevat iedere pixel één waarde, meestal tussen 0 en 1. Bij een kleurenafbeelding bevat elke pixel 3-4 waarden: Rood (R), Groen (G), Blauw (B), Optioneel transparantie (A). Een kleurenfoto kan daarom worden beschouwd als een driedimensionale tensor.
Een klassiek neuraal netwerk verwacht echter een ééndimensionale lijst als invoer. Daarom wordt vaak een techniek gebruikt die flattening heet.
Stel dat we een zwart-wit afbeelding van 28 × 28 pixels pixels hebben, dan plaatsen we eenvoudig alle rijen achter elkaar zodat één lange vector van 784 waarden ontstaat. Bij kleurenafbeeldingen voeren we dezelfde operatie uit nadat de verschillende kleurkanalen zijn samengevoegd tot een 2D Matrix.
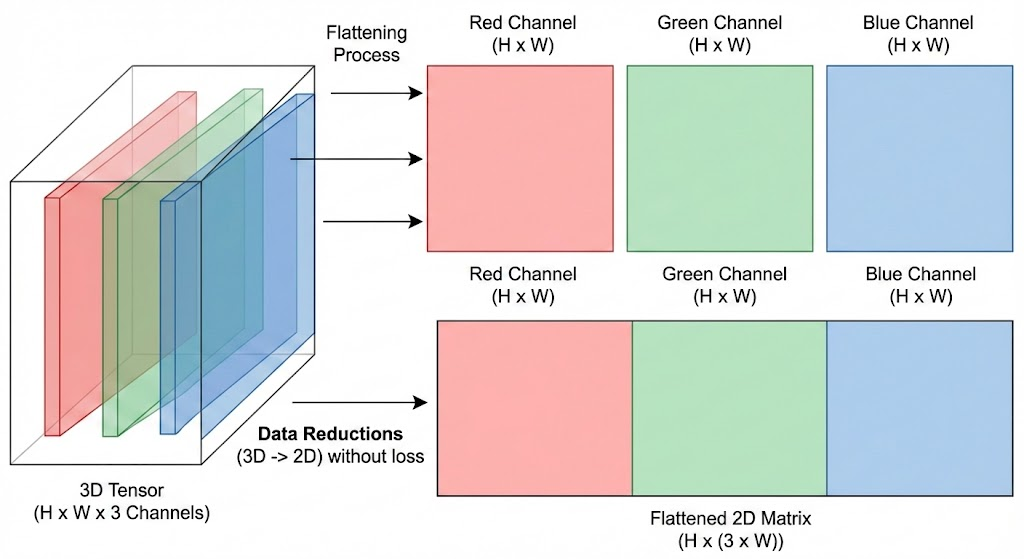
Deze transformatie is nodig om de afbeelding geschikt te maken voor neurale netwerken, al dat niet mogelijk zonder een beetje informatie te verliezen. Pixels die in de originele afbeelding naast elkaar liggen, kunnen ver uit elkaar terechtkomen in de uiteindelijke invoervector. Omgekeerd kunnen twee opeenvolgende waarden in de vector afkomstig zijn van totaal verschillende locaties in de afbeelding. Hierdoor gaat een deel van de ruimtelijke structuur verloren.
Convolutioneel netwerk
Om die reden wordt er vaak een tweede soort netwerk als pre-processing stap gebruikt. Dit Convolutional Neural Network (CNN) heeft dezelfde voordelen heeft als een neuraal netwerk, waardoor het evenwel geschikt is voor Deep Learning.
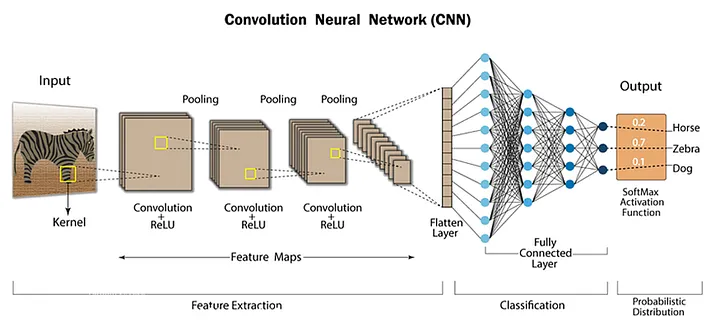
Een convolutioneel netwerk bekijkt telkens kleinere lokale gebieden van een afbeelding. In plaats van onmiddellijk alle pixels afzonderlijk te verwerken, wordt een gewogen gemiddelde genomen van een subsectie. Na meerdere convolutielagen wordt de afbeelding steeds compacter weergegeven. Waar we misschien starten met een afbeelding van 256×256 pixels, houden we uiteindelijk slechts een veel kleinere representatie over, bijvoorbeeld 16×16. Pas daarna wordt flattening toegepast.
De kettingregel zorgt ervoor dat een samenstelling van afleidbare functies 1 afleidbaar geheel vormt. Dit is essentieel voor het backpropagation-algoritme, om de richting van de verbetering te berekenen in het backpropagation algoritme. Deze richting wordt vaak de gradient genoemd. Daarnaast loopt deze optimalisatie door het volledige model, waardoor alle onderdelen gelijktijdig op elkaar kunnen worden afgestemd en geoptimaliseerd.
Tijdens de training leert het convolutionele deel betekenisvolle kenmerken uit de ruwe pixels te extraheren. Een neuron in een latere laag zou bijvoorbeeld sterk kunnen reageren (en dus een hogere waarde hebben) op:
- Diagonale lijnen
- Strepen
- Cirkelvormige patronen
- Specifieke texturen
Deze kenmerken worden vervolgens doorgegeven aan een klassiek neuraal netwerk dat de uiteindelijke classificatie uitvoert. Net omdat dit globale kenmerken zijn, kunnen we hier wel aan flattening doen. Het netwerk leert dus niet rechtstreeks wat een zebra is. In plaats daarvan leert het eerst visuele kenmerken herkennen; veel strepen aanwezig, zwart en wit zijn prominente kleuren... Daarna leert het verbanden tussen die kenmerken en de uiteindelijke categorie.
De beslissing ontstaat dus niet doordat we het expliciet programmeren, maar als een natuurlijk gevolg van de manier waarop het model leert. Dit is een mooi voorbeeld van wat emergent behavior of opkomend gedrag wordt genoemd.
Een beslissing als een natuurlijk gevolg van de manier waarop het model leert, is een mooi voorbeeld van emergent behavior.
Latente ruimte
De beslissing wordt genomen in wat men de latente of denkruimte noemt. Vaak kunnen we een neuraal netwerk daarom opsplitsen in twee functionele delen:
- Het eerste deel is verantwoordelijk voor het extraheren van relevante informatie uit de ruwe input en het omzetten daarvan naar informatieve kenmerken.
- Het tweede deel gebruikt deze kenmerken vervolgens om de uiteindelijke output te bepalen. Dit is een typisch voorbeeld van een encoder-decoderarchitectuur.
De interface tussen de twee delen van het netwerk heeft slechts een beperkte capaciteit om informatie door te geven. Omdat beide delen via backpropagation gezamenlijk worden geoptimaliseerd, proberen ze zoveel mogelijk betekenisvolle informatie in deze beperkte communicatieruimte te coderen. Het model neemt op basis van de kenmerken in deze ruimte uiteindelijk een beslissing.
Softmax-functie
De volgende vraag is dan hoe de decoder kan uitdrukken: "Op deze foto staat een kat en geen chihuahua." Bij de chihuahua-of-muffin-taak kunnen we het probleem nog formuleren als een binaire keuze en dus een booleaanse representatie gebruiken. Maar wat als het model ook katten moet kunnen herkennen?
Hiervoor kunnen we inspiratie halen uit de input transformaties van de vorige regressie-taken. Een eerste idee zou dus kunnen zijn om categorieën handmatig te nummeren, bijvoorbeeld: muffin = 1, chihuahua = 2 en kat = 3. Tijdens de training wordt deze mapping dan gebruikt als doelwaarde. Dit werkt echter alleen goed wanneer er een natuurlijke ordening bestaat tussen de categorieën, maar dit geval is een kat niet "meer" of "minder" dan een muffin of een chihuahua, waardoor deze numerieke representatie ongewenste relaties introduceert.
In dezelfde denkwijze als voorgaand bij de wagens, wordt voor deze classificatieproblemen meestal gebruikgemaakt van one-hot encoding. Voor een afbeelding van een chihuahua krijgt het output neuron dat overeenkomt met "chihuahua" de waarde 1, terwijl alle andere output neuronen de waarde 0 krijgen. Voor een kat of een muffin gebeurt precies hetzelfde. Wanneer er een nieuwe categorie wordt toegevoegd, hoeft enkel een extra output neuron te worden voorzien.
Tijdens de inferentie (het gebruiken van het model) komen de input afbeeldingen echter niet 1 op 1 overeen met de trainingsdata, waardoor de output die afwijkingen ook zal reflecteren. Om dit gedrag te handhaven kunnen we wiskundig expliciet uitdrukken dat de som van alle output neuronen 1 is, zijn zonder negatieve waarden. Deze kansverdeling heet de Softmax-functie. De beslissing wordt op die manier verdeeld over de verschillende categorieën, bijvoorbeeld:
- 85% kans op een kat,
- 10% kans op een chihuahua en
- 5% kans op een muffin.
Hierdoor verkrijgen we een vertrouwensmaatstaf dat een bepaalde detectie gemaakt is.
Leren begint bij de juiste representatie
Deep Learning draait niet alleen om neurale netwerken, maar ook om het correct representeren van problemen. Transformatietechnieken zoals numerieke encodering en one-hot encoding vertalen gegevens en afbeeldingen zodat een klassiek neuraal netwerk ermee aan de slag kan.
De kracht van Deep Learning zit uiteindelijk in het vermogen om uit ruwe numerieke representaties automatisch betekenisvolle kenmerken te leren. Zodra een probleem correct is omgezet naar getallen, kunnen neurale netwerken verrassend complexe verbanden ontdekken zonder dat we die expliciet hoeven te programmeren.
.svg)
.svg)


.png)